L’acide désoxyribonucléique ou ADN est une macromolécule biologique présente dans toutes les cellules ainsi que chez de nombreux virus. L’ADN contient toute l’information génétique, appelée génome, permettant le développement, le fonctionnement et la reproduction des êtres vivants.
C’est un acide nucléique, au même titre que l’acide ribonucléique (ARN). Les acides nucléiques sont, avec les peptides et les glucides, l’une des trois grandes familles de biopolymères essentiels à toutes les formes de vie connues.
Les molécules d’ADN des cellules vivantes sont formées de deux brins antiparallèles enroulés l’un autour de l’autre pour former une double hélice. On dit que l’ADN est bicaténaire, ou double brin. Chacun de ces brins est un polymère appelé polynucléotide. Chaque monomère qui le constitue est un nucléotide, lequel est formé d’une base nucléique, ou base azotée — adénine (A), cytosine (C), guanine (G) ou thymine (T) — liée à un ose — ici, le désoxyribose — lui-même lié à un groupe phosphate. Les nucléotides polymérisés sont unis les uns aux autres par des liaisons covalentes entre le désoxyribose d’un nucléotide et le groupe phosphate du nucléotide suivant, formant ainsi une chaîne où alternent oses et phosphates, avec des bases nucléiques liées chacune à un ose. L’ordre dans lequel se succèdent les nucléotides le long d’un brin d’ADN constitue la séquence de ce brin. C’est cette séquence qui porte l’information génétique. Celle-ci est structurée en gènes, qui sont exprimés à travers la transcription en ARN. Ces ARN peuvent être non codants — ARN de transfert et ARN ribosomique notamment — ou bien codants : il s’agit dans ce cas d’ARN messagers, qui sont traduits en protéines par des ribosomes. La succession des bases nucléiques sur l’ADN détermine la succession des acides aminés qui constituent les protéines issues de ces gènes. La correspondance entre bases nucléiques et acides aminés est le code génétique. L’ensemble des gènes d’un organisme constitue son génome.
Les bases nucléiques d’un brin d’ADN peuvent interagir avec les bases nucléiques d’un autre brin d’ADN à travers des liaisons hydrogène, qui déterminent des règles d’appariement entre paires de bases : l’adénine et la thymine s’apparient au moyen de deux liaisons hydrogène, tandis que la guanine et la cytosine s’apparient au moyen de trois liaisons hydrogène. Normalement, l’adénine et la cytosine ne s’apparient pas, tout comme la guanine et la thymine. Lorsque les séquences des deux brins sont complémentaires, ces brins peuvent s’apparier en formant une structure bicaténaire hélicoïdale caractéristique qu’on appelle double hélice d’ADN. Cette double hélice est bien adaptée au stockage de l’information génétique : la chaîne oses-phosphates est résistante aux réactions de clivage ; de plus, l’information est dupliquée sur les deux brins de la double hélice, ce qui permet de réparer un brin endommagé à partir de l’autre brin resté intact ; enfin, cette information peut être copiée à travers un mécanisme appelé réplication de l’ADN au cours duquel une double hélice d’ADN est recopiée fidèlement en une autre double hélice portant la même information. C’est en particulier ce qu’il se passe lors de la division cellulaire : chaque molécule d’ADN de la cellule mère est répliquée en deux molécules d’ADN, chacune des deux cellules filles recevant ainsi un jeu complet de molécules d’ADN, chaque jeu étant identique à l’autre.
Dans les cellules, l’ADN est organisé en structures appelées chromosomes. Ces chromosomes ont pour fonction de rendre l’ADN plus compact à l’aide de protéines, notamment d’histones, qui forment, avec les acides nucléiques, une substance appelée chromatine. Les chromosomes participent également à la régulation de l’expression génétique en déterminant quelles parties de l’ADN doivent être transcrites en ARN. Chez les eucaryotes (animaux, plantes, champignons et protistes), l’ADN est essentiellement contenu dans le noyau des cellules, avec une fraction d’ADN présent également dans les mitochondries ainsi que, chez les plantes, dans les chloroplastes. Chez les procaryotes (bactéries et archées), l’ADN est contenu dans le cytoplasme. Chez les virus qui contiennent de l’ADN, celui-ci est stocké dans la capside. Quel que soit l’organisme considéré, l’ADN est transmis au cours de la reproduction : il joue le rôle de support de l’hérédité. La modification de la séquence des bases d’un gène peut conduire à une mutation génétique, laquelle peut, selon les cas, être bénéfique, sans conséquence ou néfaste pour l’organisme, voire incompatible avec sa survie. À titre d’exemple, la modification d’une seule base d’un seul gène — celui de la β-globine, une sous-unité protéique de l’hémoglobine A — du génotype humain est responsable de la drépanocytose, une maladie génétique parmi les plus répandues dans le monde.

L’ADN est un long polymère formé par la répétition de monomères appelés nucléotides. Le premier ADN a été identifié et isolé en 1869 à partir du noyau de globules blancs par le Suisse Friedrich Miescher. Sa structure en double hélice a été mise en évidence en 1953 par le Britannique Francis Crick et

l’Américain James Watson à partir des données expérimentales obtenues par les Britanniques Rosalind Franklin et Maurice Wilkins. Cette structure, commune à toutes les espèces, est constituée de deux chaînes polynucléotidiques hélicoïdales enroulées l’une autour de l’autre autour d’un axe commun, avec un pas d’environ 3,4 nm pour un diamètre d’environ 2,0 nm1. Une autre étude mesurant les paramètres géométriques de l’ADN en solution donne un diamètre de 2,2 à 2,6 nm avec une longueur par nucléotide de 0,33 nm2. Bien que chaque nucléotide soit très petit, les molécules d’ADN peuvent en contenir des millions et atteindre des dimensions significatives. Par exemple, le chromosome 1 humain, qui est le plus grand des chromosomes humains, contient environ 220 millions de paires de bases3 pour une longueur linéaire de plus de 7 cm.

Dans les cellules vivantes, l’ADN n’existe généralement pas sous forme monocaténaire (simple brin) mais plutôt sous forme bicaténaire (double brin) avec une configuration en double hélice1. Les monomères constituant chaque brin d’ADN comprennent un segment de la chaîne désoxyribose–phosphate et une base nucléique liée au désoxyribose. La molécule résultant de la liaison d’une base nucléique à un ose est appelée nucléoside ; l’adjonction d’un à trois groupes phosphate à l’ose d’un nucléoside forme un nucléotide. Un polymère résultant de la polymérisation de nucléotides est appelé polynucléotide. L’ADN et l’ARN sont des polynucléotides.
L’ose constituant le squelette de la molécule est le 2’-désoxyribose, dérivé du ribose. Ce pentose alterne avec des groupes phosphate en formant des liaisons phosphodiester entre les atomes no 3’ et no 5’ de résidus de désoxyribose adjacents4. En raison de cette liaison asymétrique, les brins d’ADN ont un sens. Dans une double hélice, les deux brins d’ADN sont de sens opposés : ils sont dits antiparallèles. Le sens 5’ vers 3’ d’un brin d’ADN désigne conventionnellement celui de l’extrémité portant un groupe phosphate –PO32− vers l’extrémité portant un groupe hydroxyle –OH ; c’est dans ce sens qu’est synthétisé l’ADN par les ADN polymérases. L’une des grandes différences entre l’ADN et l’ARN est le fait que l’ose du squelette de la molécule est le ribose dans le cas de l’ARN à la place du désoxyribose de l’ADN, ce qui joue sur la stabilité et la géométrie de cette macromolécule.

L’ADN est un long polymère formé par la répétition de monomères appelés nucléotides. Le premier ADN a été identifié et isolé en 1869 à partir du noyau de globules blancs par le Suisse Friedrich Miescher. Sa structure en double hélice a été mise en évidence en 1953 par le Britannique Francis Crick et l’Américain James Watson à partir des données expérimentales obtenues par les Britanniques Rosalind Franklin et Maurice Wilkins. Cette structure, commune à toutes les espèces, est constituée de deux chaînes polynucléotidiques hélicoïdales enroulées l’une autour de l’autre autour d’un axe commun, avec un pas d’environ 3,4 nm pour un diamètre d’environ 2,0 nm1. Une autre étude mesurant les paramètres géométriques de l’ADN en solution donne un diamètre de 2,2 à 2,6 nm avec une longueur par nucléotide de 0,33 nm2. Bien que chaque nucléotide soit très petit, les molécules d’ADN peuvent en contenir des millions et atteindre des dimensions significatives. Par exemple, le chromosome 1 humain, qui est le plus grand des chromosomes humains, contient environ 220 millions de paires de bases3 pour une longueur linéaire de plus de 7 cm.

Dans les cellules vivantes, l’ADN n’existe généralement pas sous forme monocaténaire (simple brin) mais plutôt sous forme bicaténaire (double brin) avec une configuration en double hélice1. Les monomères constituant chaque brin d’ADN comprennent un segment de la chaîne désoxyribose–phosphate et une base nucléique liée au désoxyribose. La molécule résultant de la liaison d’une base nucléique à un ose est appelée nucléoside ; l’adjonction d’un à trois groupes phosphate à l’ose d’un nucléoside forme un nucléotide. Un polymère résultant de la polymérisation de nucléotides est appelé polynucléotide. L’ADN et l’ARN sont des polynucléotides.
L’ose constituant le squelette de la molécule est le 2’-désoxyribose, dérivé du ribose. Ce pentose alterne avec des groupes phosphate en formant des liaisons phosphodiester entre les atomes no 3’ et no 5’ de résidus de désoxyribose adjacents4. En raison de cette liaison asymétrique, les brins d’ADN ont un sens. Dans une double hélice, les deux brins d’ADN sont de sens opposés : ils sont dits antiparallèles. Le sens 5’ vers 3’ d’un brin d’ADN désigne conventionnellement celui de l’extrémité portant un groupe phosphate –PO32− vers l’extrémité portant un groupe hydroxyle –OH ; c’est dans ce sens qu’est synthétisé l’ADN par les ADN polymérases. L’une des grandes différences entre l’ADN et l’ARN est le fait que l’ose du squelette de la molécule est le ribose dans le cas de l’ARN à la place du désoxyribose de l’ADN, ce qui joue sur la stabilité et la géométrie de cette macromolécule.
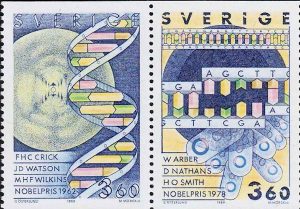
L’ADN est un long polymère formé par la répétition de monomères appelés nucléotides. Le premier ADN a été identifié et isolé en 1869 à partir du noyau de globules blancs par le Suisse Friedrich Miescher. Sa structure en double hélice a été mise en évidence en 1953 par le Britannique Francis Crick et l’Américain James Watson à partir des données expérimentales obtenues par les Britanniques Rosalind Franklin et Maurice Wilkins. Cette structure, commune à toutes les espèces, est constituée de deux chaînes polynucléotidiques hélicoïdales enroulées l’une autour de l’autre autour d’un axe commun, avec un pas d’environ 3,4 nm pour un diamètre d’environ 2,0 nm1. Une autre étude mesurant les paramètres géométriques de l’ADN en solution donne un diamètre de 2,2 à 2,6 nm avec une longueur par nucléotide de 0,33 nm2. Bien que chaque nucléotide soit très petit, les molécules d’ADN peuvent en contenir des millions et atteindre des dimensions significatives. Par exemple, le chromosome 1 humain, qui est le plus grand des chromosomes humains, contient environ 220 millions de paires de bases3 pour une longueur linéaire de plus de 7 cm.
Dans les cellules vivantes, l’ADN n’existe généralement pas sous forme monocaténaire (simple brin) mais plutôt sous forme bicaténaire (double brin) avec une configuration en double hélice1. Les monomères constituant chaque brin d’ADN comprennent un segment de la chaîne désoxyribose–phosphate et une base nucléique liée au désoxyribose. La molécule résultant de la liaison d’une base nucléique à un ose est appelée nucléoside ; l’adjonction d’un à trois groupes phosphate à l’ose d’un nucléoside forme un nucléotide. Un polymère résultant de la polymérisation de nucléotides est appelé polynucléotide. L’ADN et l’ARN sont des polynucléotides.

L’ose constituant le squelette de la molécule est le 2’-désoxyribose, dérivé du ribose. Ce pentose alterne avec des groupes phosphate en formant des liaisons phosphodiester entre les atomes no 3’ et no 5’ de résidus de désoxyribose adjacents4. En raison de cette liaison asymétrique, les brins d’ADN ont un sens. Dans une double hélice, les deux brins d’ADN sont de sens opposés : ils sont dits antiparallèles. Le sens 5’ vers 3’ d’un brin d’ADN désigne conventionnellement celui de l’extrémité portant un groupe phosphate –PO32− vers l’extrémité portant un groupe hydroxyle –OH ; c’est dans ce sens qu’est synthétisé l’ADN par les ADN polymérases. L’une des grandes différences entre l’ADN et l’ARN est le fait que l’ose du squelette de la molécule est le ribose dans le cas de l’ARN à la place du désoxyribose de l’ADN, ce qui joue sur la stabilité et la géométrie de cette macromolécule.
L’ADN est un long polymère formé par la répétition de monomères appelés nucléotides. Le premier ADN a été identifié et isolé en 1869 à partir du noyau de globules blancs par le Suisse Friedrich Miescher. Sa structure en double hélice a été mise en évidence en 1953 par le Britannique Francis Crick et l’Américain James Watson à partir des données expérimentales obtenues par les Britanniques Rosalind Franklin et Maurice Wilkins. Cette structure, commune à toutes les espèces, est constituée de deux chaînes polynucléotidiques hélicoïdales enroulées l’une autour de l’autre autour d’un axe commun, avec un pas d’environ 3,4 nm pour un diamètre d’environ 2,0 nm1. Une autre étude mesurant les paramètres géométriques de l’ADN en solution donne un diamètre de 2,2 à 2,6 nm avec une longueur par nucléotide de 0,33 nm2. Bien que chaque nucléotide soit très petit, les molécules d’ADN peuvent en contenir des millions et atteindre des dimensions significatives. Par exemple, le chromosome humain, qui est le plus grand des chromosomes humains, contient environ 220 millions de paires de bases3 pour une longueur linéaire de plus de 7 cm.

Dans les cellules vivantes, l’ADN n’existe généralement pas sous forme monocaténaire (simple brin) mais plutôt sous forme bicaténaire (double brin) avec une configuration en double hélice1. Les monomères constituant chaque brin d’ADN comprennent un segment de la chaîne désoxyribose–phosphate et une base nucléique liée au désoxyribose. La molécule résultant de la liaison d’une base nucléique à un ose est appelée nucléoside ; l’adjonction d’un à trois groupes phosphate à l’ose d’un nucléoside forme un nucléotide. Un polymère résultant de la polymérisation de nucléotides est appelé polynucléotide. L’ADN et l’ARN sont des polynucléotides.
L’ose constituant le squelette de la molécule est le 2’-désoxyribose, dérivé du ribose. Ce pentose alterne avec des groupes phosphate en formant des liaisons phosphodiester entre les atomes no 3’ et no 5’ de résidus de désoxyribose adjacents. En raison de cette liaison asymétrique, les brins d’ADN ont un sens. Dans une double hélice, les deux brins d’ADN sont de sens opposés : ils sont dits antiparallèles. Le sens 5’ vers 3’ d’un brin d’ADN désigne conventionnellement celui de l’extrémité portant un groupe phosphate –PO32− vers l’extrémité portant un groupe hydroxyle –OH ; c’est dans ce sens qu’est synthétisé l’ADN par les ADN polymérases. L’une des grandes différences entre l’ADN et l’ARN est le fait que l’ose du squelette de la molécule est le ribose dans le cas de l’ARN à la place du désoxyribose de l’ADN, ce qui joue sur la stabilité et la géométrie de cette macromolécule.
Voir aussi cette vidéo :
Sources : Wikipédia, YouTube.